PDF Chat with Node.js, OpenAI and ModelFusion
Have you ever wondered how a chatbot that can answer questions about a PDF works?


In this blog post, we'll build a console app capable of searching and understanding PDF content to answer questions using Node.js, OpenAI, and ModelFusion. You'll learn how to read and index PDFs for efficient search and deliver precise responses by retrieving relevant content from the PDFs.
You can find the complete code for the chatbot here: github/com/lgrammel/modelfusion/examples/pdf-chat-terminal
This blog post explains the essential parts in detail. Let's get started!
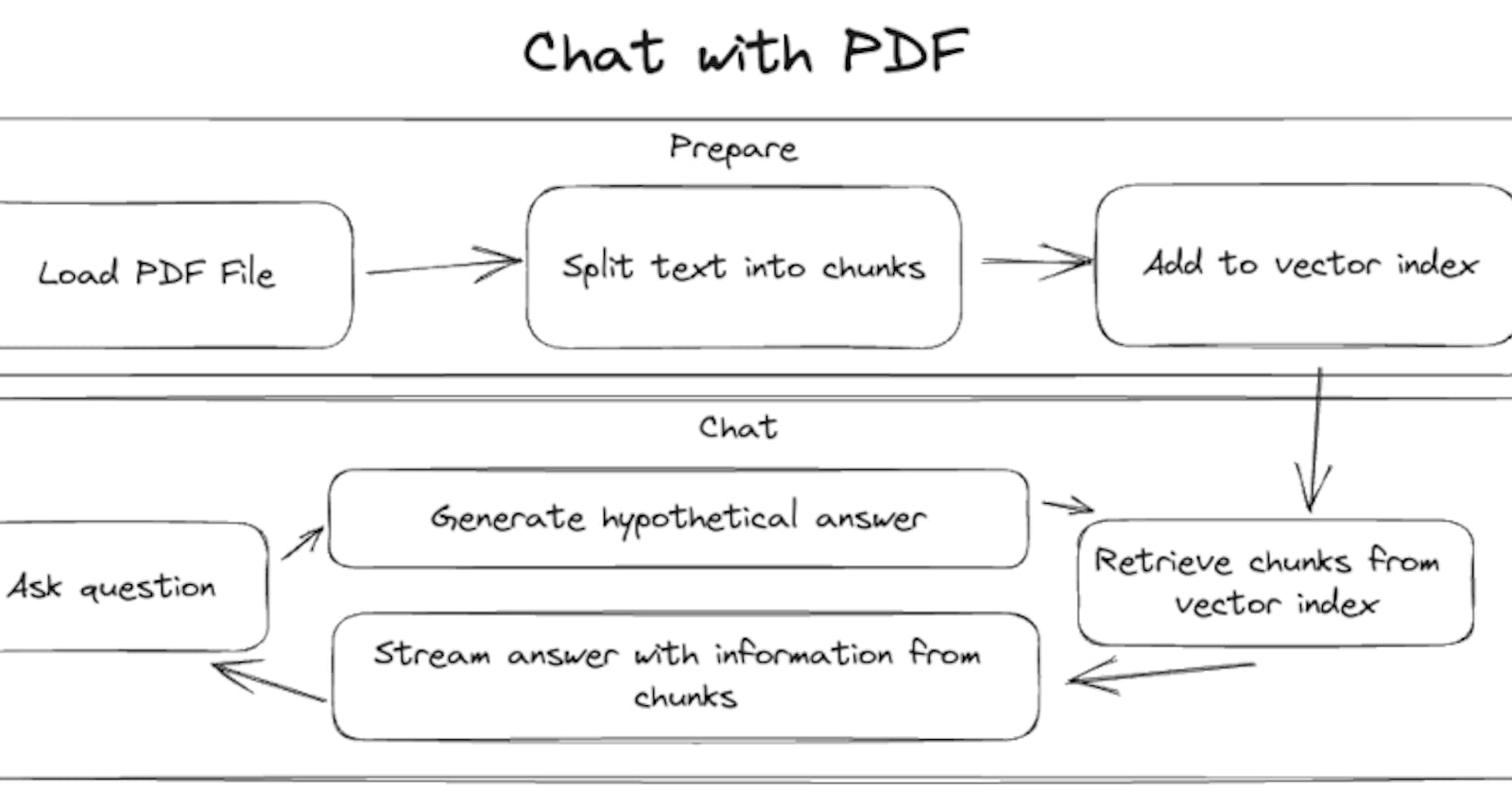
Loading Pages from PDFs
We use Mozilla's PDF.js via the pdfjs-dist NPM module to load pages from a PDF file. The loadPdfPages function reads the PDF file and extracts its content. It returns an array where each object contains the page number and the text of that page.
import fs from "fs/promises";
import * as PdfJs from "pdfjs-dist/legacy/build/pdf";
async function loadPdfPages(path: string) {
const pdfData = await fs.readFile(path);
const pdf = await PdfJs.getDocument({
data: new Uint8Array(
pdfData.buffer,
pdfData.byteOffset,
pdfData.byteLength
),
useSystemFonts: true,
}).promise;
const pageTexts: Array<{
pageNumber: number;
text: string;
}> = [];
for (let i = 0; i < pdf.numPages; i++) {
const page = await pdf.getPage(i + 1);
const pageContent = await page.getTextContent();
pageTexts.push({
pageNumber: i + 1,
text: pageContent.items
.filter((item) => (item as any).str != null)
.map((item) => (item as any).str as string)
.join(" ")
.replace(/\s+/g, " "),
});
}
return pageTexts;
}
Let's explore the primary tasks: "Load & Parse PDF" and "Extract Page Numbers and Text."
Load & parse the PDF
Before working with the PDF content, we need to read the file from the disk and parse it into a format our code can understand.
const pdfData = await fs.readFile(path);
const pdf = await PdfJs.getDocument({
data: new Uint8Array(pdfData.buffer, pdfData.byteOffset, pdfData.byteLength),
useSystemFonts: true,
}).promise;
In this code snippet, the fs.readFile function reads the PDF file from the disk and stores the data in pdfData. We then use the PdfJs.getDocument function to parse this data. The flag useSystemFonts is set to true to avoid issues when system fonts are used in the PDF.
Extract page numbers and text
After successfully loading and parsing the PDF, the next step is to extract the text content from each page along with its page number.
const pageTexts: Array<{
pageNumber: number;
text: string;
}> = [];
for (let i = 0; i < pdf.numPages; i++) {
const page = await pdf.getPage(i + 1);
const pageContent = await page.getTextContent();
pageTexts.push({
pageNumber: i + 1,
text: pageContent.items
.filter((item) => (item as any).str != null)
.map((item) => (item as any).str as string)
.join(" ")
.replace(/\s+/g, " "),
}
The code defines an array named pageTexts to hold objects that contain the page number and the extracted text from each page. We then loop through each page of the PDF by using pdf.numPages to determine the total number of pages.
Within the loop, pdf.getPage(i + 1) fetches each page, starting from page number 1. We extract the text content with page.getTextContent().
Finally, the extracted text from each page is cleaned up by joining all text items and reducing multiple whitespaces to a single space. This cleaned-up text and the page number are stored in pageTexts.
Indexing Pages
Now that the PDF pages are available as text, we'll delve into the mechanism for indexing the PDF text we've loaded. Indexing is crucial as it allows for quick and semantic-based retrieval of information later. Here's how the magic happens:
const pages = await loadPdfPages(file);
const embeddingModel = new OpenAITextEmbeddingModel({
model: "text-embedding-ada-002",
throttle: throttleMaxConcurrency({ maxConcurrentCalls: 5 }),
});
const chunks = await splitTextChunks(
splitAtToken({
maxTokensPerChunk: 256,
tokenizer: embeddingModel.tokenizer,
}),
pages
);
const vectorIndex = new MemoryVectorIndex<{
pageNumber: number;
text: string;
}>();
await upsertTextChunks({ vectorIndex, embeddingModel, chunks });
Let's look at each step:
Initialize the text embedding model
The first step is to initialize a text embedding model. This model will be responsible for converting our text data into a format that can be compared for similarity.
const embeddingModel = new OpenAITextEmbeddingModel({
model: "text-embedding-ada-002",
throttle: throttleMaxConcurrency({ maxConcurrentCalls: 5 }),
});
Text embedding models work by converting chunks of text into vectors in a multi-dimensional space such that text with similar meaning will have vectors that are close to each other. These vectors will be stored in a vector index.
Tokenization and text chunking
We need to prepare the text data before we convert our text into vectors. This preparation involves splitting the text into smaller pieces, known as "chunks," that are manageable for the model.
const chunks = await splitTextChunks(
splitAtToken({
maxTokensPerChunk: 256,
tokenizer: embeddingModel.tokenizer,
}),
pages
);
We limit each chunk to 256 tokens and use the tokenizer from our embedding model. The splitTextChunks function recursively splits the text until the chunks fit the specified maximum size.
You can play with the chunk size and see how it affects the results. When chunks are too small, they might contain only some of the necessary information to answer a question. When chunks are too large, their embedding vector may not be similar enough to the hypothetical answer we generate later.
Token: A token is the smallest unit that a machine-learning model reads. In language models, a token can be as small as a character or as long as a word (e.g., 'a', 'apple').
Tokenizer: A tool that breaks down text into tokens. ModelFusion provides the tokenizer for most text generation and embedding models.
Creating a memory vector index
The next step is to create an empty memory vector index to store our embedded text vectors.
const vectorIndex = new MemoryVectorIndex<{
pageNumber: number;
text: string;
}>();
A vector store is like a specialized database for vectors. It allows us to perform quick searches to find similar vectors to a given query vector.
In ModelFusion, a vector index is a searchable interface to access a vector store for a specific table or metadata. In our app, each vector in the index is associated with the page number and the text chunk it originated from.
The ModelFusion MemoryVectorIndex is a simple in-memory implementation of a vector index that uses cosine similarity to find similar vectors. It's a good choice for small datasets, such as a single PDF file loaded on-demand.
Inserting text chunks into the vector index
Finally, we populate our memory vector index with the text vectors generated from our chunks.
await upsertTextChunks({ vectorIndex, embeddingModel, chunks });
The function upsertTextChunks performs the following:
It uses the
embeddingModelto convert each text chunk into a vector.It then inserts this vector into
vectorIndex, along with the metadata (page number and text).
At this point, our vector index is fully populated and ready for fast, semantic-based searches. This is essential for our chatbot to provide relevant and accurate answers.
In summary, indexing involves converting text chunks into a vectorized, searchable format. It the stage for semantic-based text retrieval, enabling our chatbot to understand and respond in a context-aware manner.
The Chat Loop
The chat loop is the central part of our "Chat with PDF" application. It continuously awaits user questions, generates hypothetical answers, searches for similar text chunks from a pre-processed PDF, and responds to the user.
const chat = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
while (true) {
const question = await chat.question("You: ");
const hypotheticalAnswer = await generateText({
model: openai.ChatTextGenerator({ model: "gpt-3.5-turbo", temperature: 0 }),
prompt: [
openai.ChatMessage.system(`Answer the user's question.`),
openai.ChatMessage.user(question),
],
});
const information = await retrieve(
new VectorIndexRetriever({
vectorIndex,
embeddingModel,
maxResults: 5,
similarityThreshold: 0.75,
}),
hypotheticalAnswer
);
const textStream = await streamText({
model: openai.ChatTextGenerator({ model: "gpt-4", temperature: 0 }),
prompt: [
openai.ChatMessage.system(
`Answer the user's question using only the provided information.\n` +
`Include the page number of the information that you are using.\n` +
`If the user's question cannot be answered using the provided information, ` +
`respond with "I don't know".`
),
openai.ChatMessage.user(question),
openai.ChatMessage.fn({
fnName: "getInformation",
content: JSON.stringify(information),
}),
],
});
process.stdout.write("\nAI : ");
for await (const textFragment of textStream) {
process.stdout.write(textFragment);
}
process.stdout.write("\n\n");
}
Let's break down the major components of the code within the chat loop.
Looping and waiting for user input
const chat = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
while (true) {
const question = await chat.question("You: ");
// ...
}
The chat loop runs indefinitely to keep the chat interaction alive. We use the Node.js readline package for collecting user input from the terminal on each iteration.
Generate a hypothetical answer
const hypotheticalAnswer = await generateText({
model: openai.ChatTextGenerator({ model: "gpt-3.5-turbo", temperature: 0 }),
prompt: [
openai.ChatMessage.system(`Answer the user's question.`),
openai.ChatMessage.user(question),
],
});
We use the gpt-3.5-turbo model from OpenAI to create a hypothetical answer first.
The idea (hypothetical document embeddings) is that the hypothetical answer will be closer to the chunks we seek in the embedding vector space than the user's question. This approach will help us to find better results when searching for similar text chunks later.
Retrieve relevant text chunks
const { chunks: information } = await retrieveTextChunks(
new SimilarTextChunksFromVectorIndexRetriever({
vectorIndex,
embeddingModel,
maxResults: 5,
similarityThreshold: 0.75,
}),
hypotheticalAnswer
);
The retrieveTextChunks() function searches for text chunks similar to the hypothetical answer from the pre-processed PDF.
We limit the results to 5 and set a similarity threshold of 0.75. You can play with these parameters (in combination with the earlier chunk size setting) to see how they affect the results. When you e.g., make the chunks smaller, you might want to increase the number of results to get more information.
Generate an answer using text chunks
const textStream = await streamText({
model: openai.ChatTextGenerator({ model: "gpt-4", temperature: 0 }),
prompt: [
openai.ChatMessage.system(
`Answer the user's question using only the provided information.\n` +
`Include the page number of the information that you are using.\n` +
`If the user's question cannot be answered using the provided information, ` +
`respond with "I don't know".`
),
openai.ChatMessage.user(question),
openai.ChatMessage.functionResult(
"getInformation",
JSON.stringify(information)
),
],
});
We use gpt-4 to generate a final answer based on the retrieved text chunks. The temperature is set to 0 to remove as much randomness as possible from the response.
In the system prompt, we specify that:
The answer should be based solely on the retrieved text chunks.
The page number of the information should be included.
The answer should be "I don't know" if the user's question cannot be answered using the provided information. This instruction steers the LLM towards using this answer if it cannot find the answer in the text chunks.
The chunks are inserted as fake function results (using the OpenAI function calling API) to indicate that they are separate from the user's question.
The answer is streamed to show information to the user as soon as it is available.
Stream the answer to the console
process.stdout.write("\nAI : ");
for await (const textFragment of textStream) {
process.stdout.write(textFragment);
}
process.stdout.write("\n\n");
Finally, we display the generated answer to the user using stdout.write() to print the text fragments collected from textStream.
Conclusion
That wraps up our journey into building a chatbot capable of answering questions based on PDF content. With the help of OpenAI and ModelFusion, you've seen how to read, index, and retrieve information from PDF files.
The code is intended as a starting point for your projects. Have fun exploring!
P.S.: You can find the complete code for the application here: github.com/lgrammel/modelfusion/examples/pdf-chat-terminal